Point Cloud Object Detection and Pose Estimation
Objective
Shape-Based Remote Manipulation (NSF): We are building an operating interface coupled with a manipulator that promises communication across the distance barrier.
My Focus: As the first stage of this project, I am responsible for developing a perception system to sense the manipulator’s environment.
Goal: This project aims to design a computer vision setup and implement software to detect objects and estimate their poses in 3D space.
Video demo
Hardware
- Intel Realsense Lidar L515
Intel realsense L515 uses a solid-state Lidar to sense depth. The Lidar can provide organized point clouds. It also has an RGB camera which is calibrated with the Lidar.
Pipeline
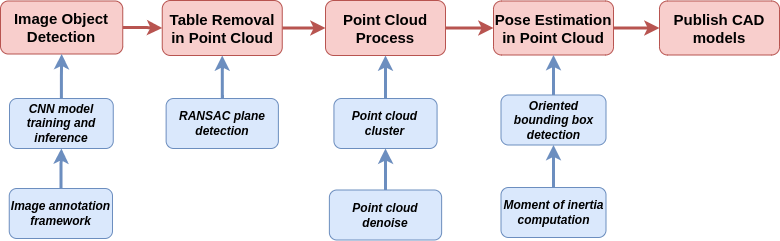
software
The software of this project can be explained in two stages based on the two ROS nodes I have in the project:
- Inference server
- Perception core
Inference server
The inference server is a ROS node that runs a deep learning model (CNN) to detect objects in the image space. The inference server is implemented in Python using Detectron2 and Pytorch as the deep learning framework. For the use case of this project, a custom dataset is created to train the model. Mask-RCNN is used as the model architecture since we need to implement instance segmentation. The model was then trained with 100 self-labeled images with an ontology of a “cheez-it” box. The labeled images are shown below:

The images are annotated on an open-sourced platform, CVAT. CVAT provides many tools to accelerate the labeling processes and improve the qualities, such as machine learning models.
The model was then trained using Detectron2 with 100 labeled images. The inference results are shown below:

The inference server subscribes to the image topic and computes the target object masks. The inference server then publishes the masks to the perception core node.
Perception core
The perception core is a ROS node that performs the following tasks:
- Receives both the point cloud from the LiDAR and the image from the RGB camera
- Detects the table in point cloud data and removes it
- Denoises, downsamples, and clusters the point cloud data to create a foreground mask
- Receives the target object masks from the inference server and gets a inference mask
- merge the foreground mask and the inference mask to get a final mask
- Performs oriented bounding box detection and pose estimation on the final mask with a state machine
The perception core is implemented in C++ using ROS. The node uses PCL for the point cloud process and OpenCV for the image process. The organized point cloud acquired from the realsense Lidar helped significantly reduce the perception core’s runtime. The algorithms in the node were implemented to keep the organized point cloud using a customized data structure, OrderedCloud. Moreover, some algorithms were implemented in image space to reduce the runtime, such as denoise, downsample, and cluster. As a result, the node can be run efficiently with real-time performance. A state machine controls the detection and pose estimation processes based on the motion in the image space.
The below image shows the table removal process:
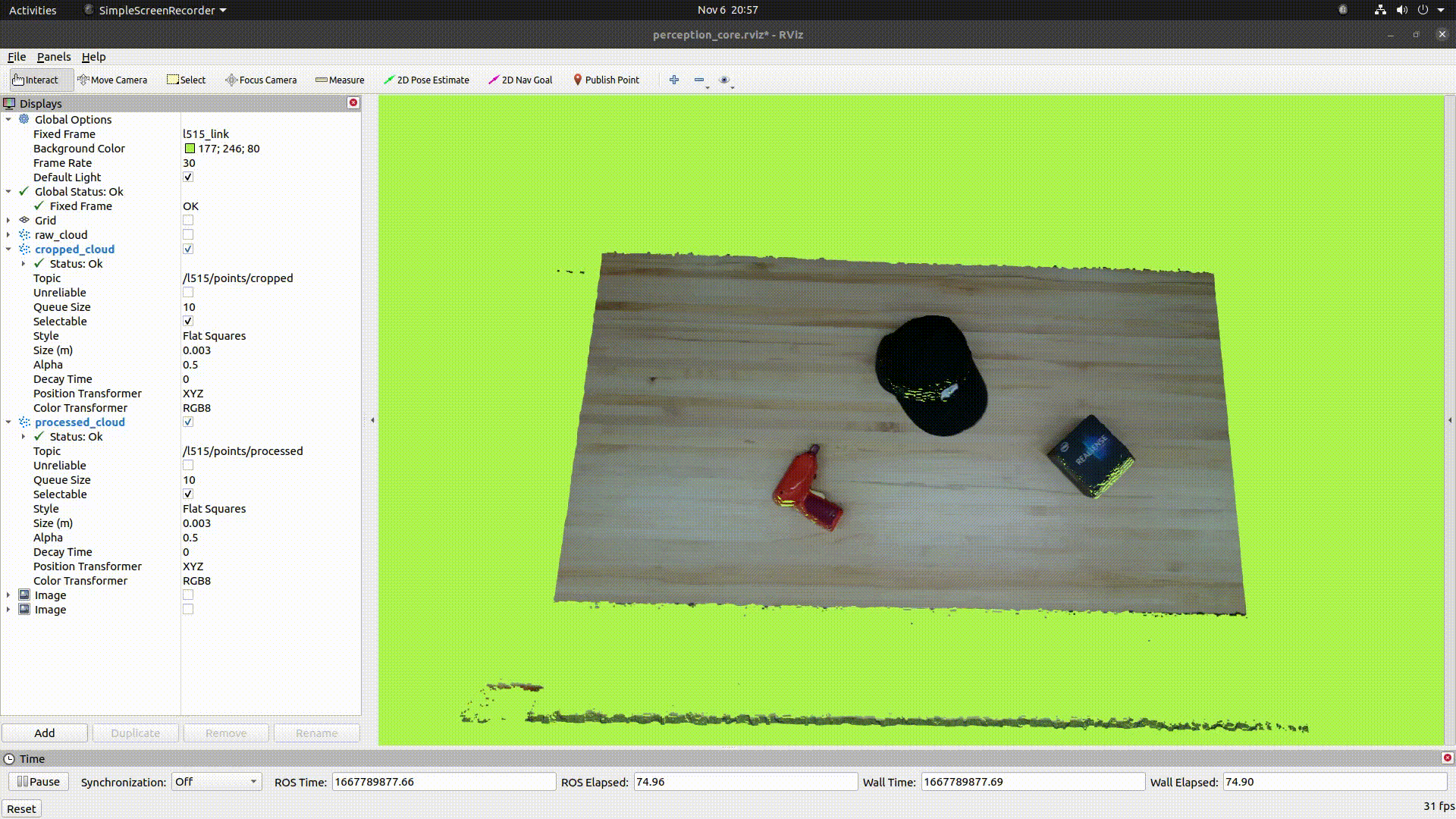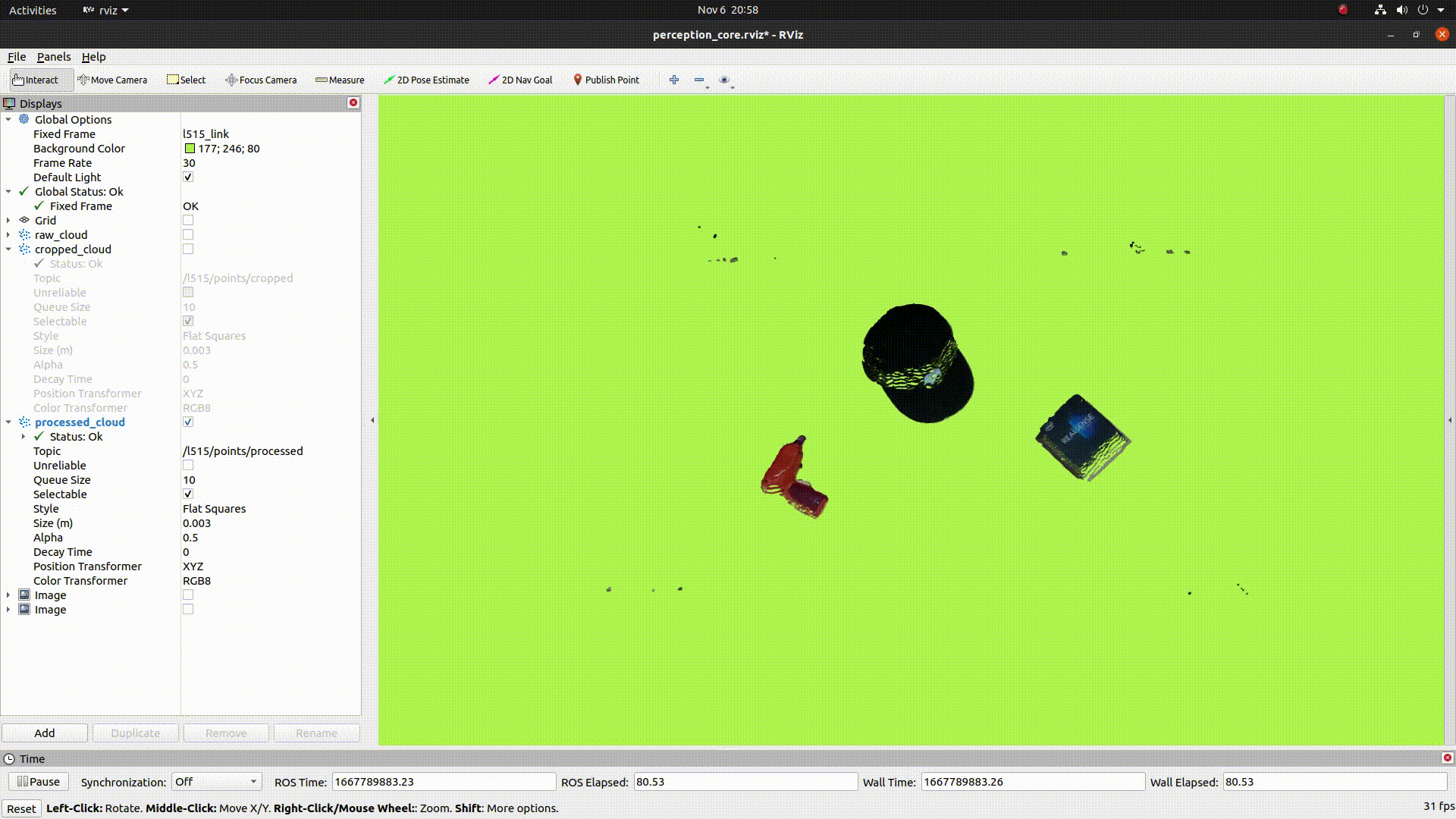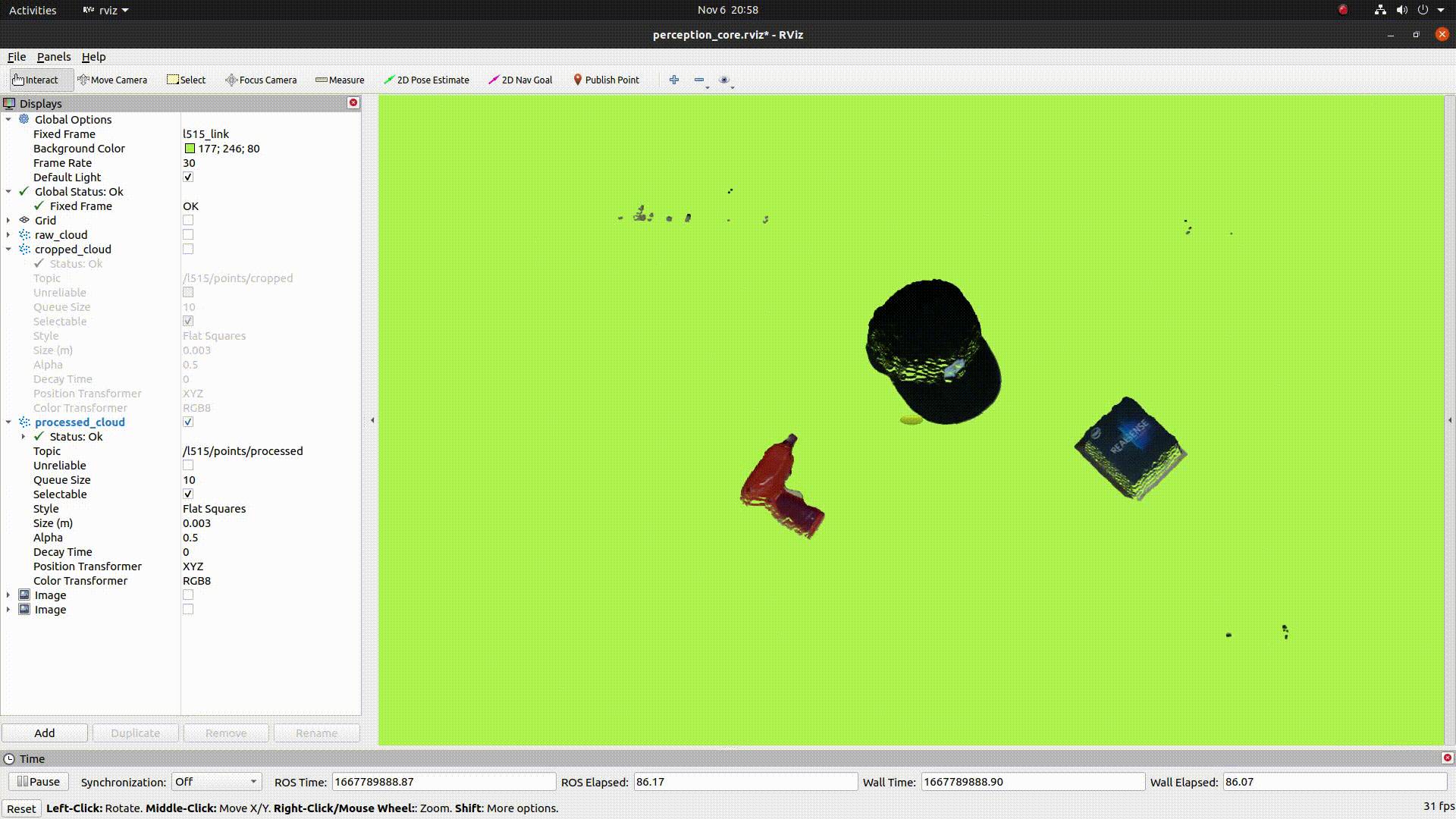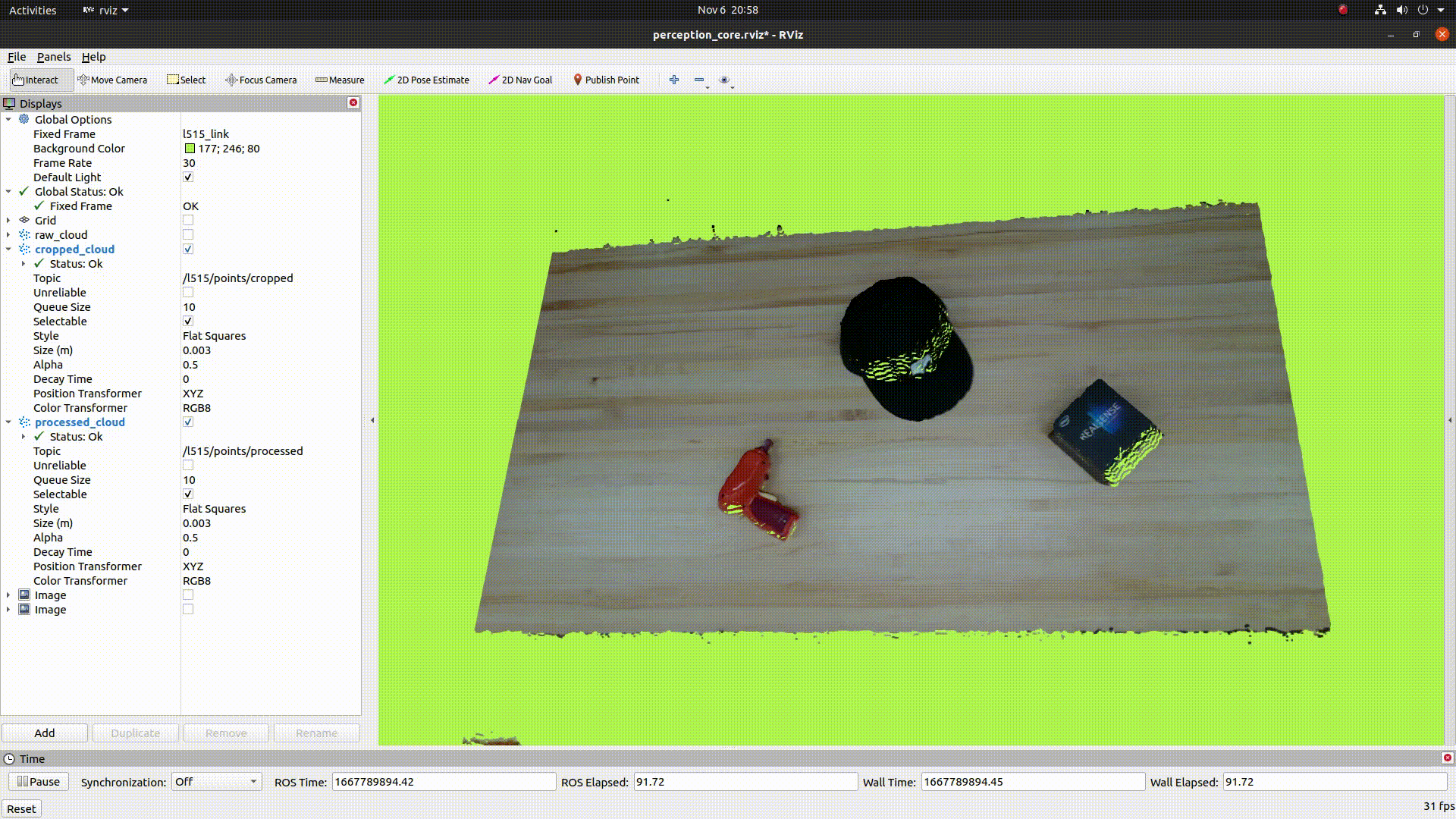
The below image shows the colorized point cloud clusters after denoising, downsampling, and clustering:
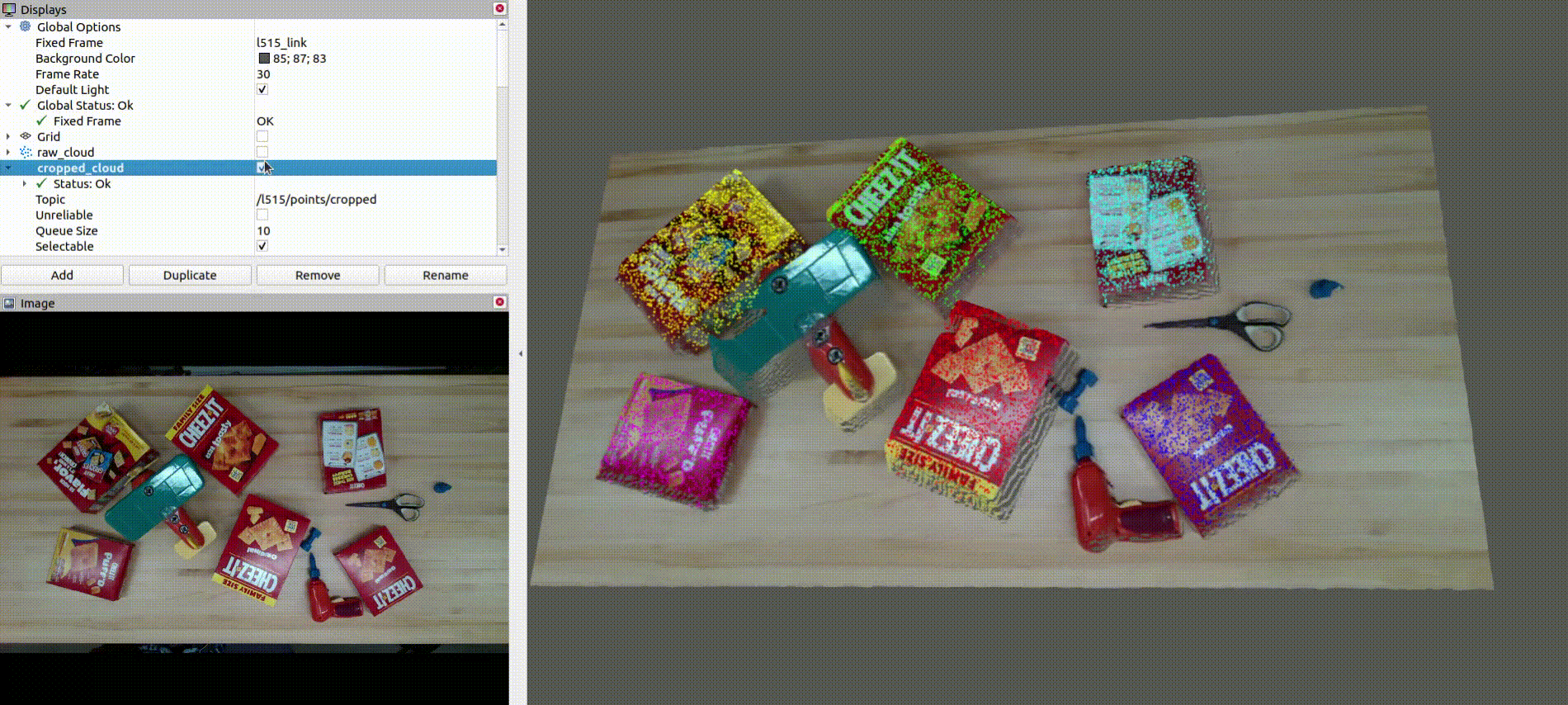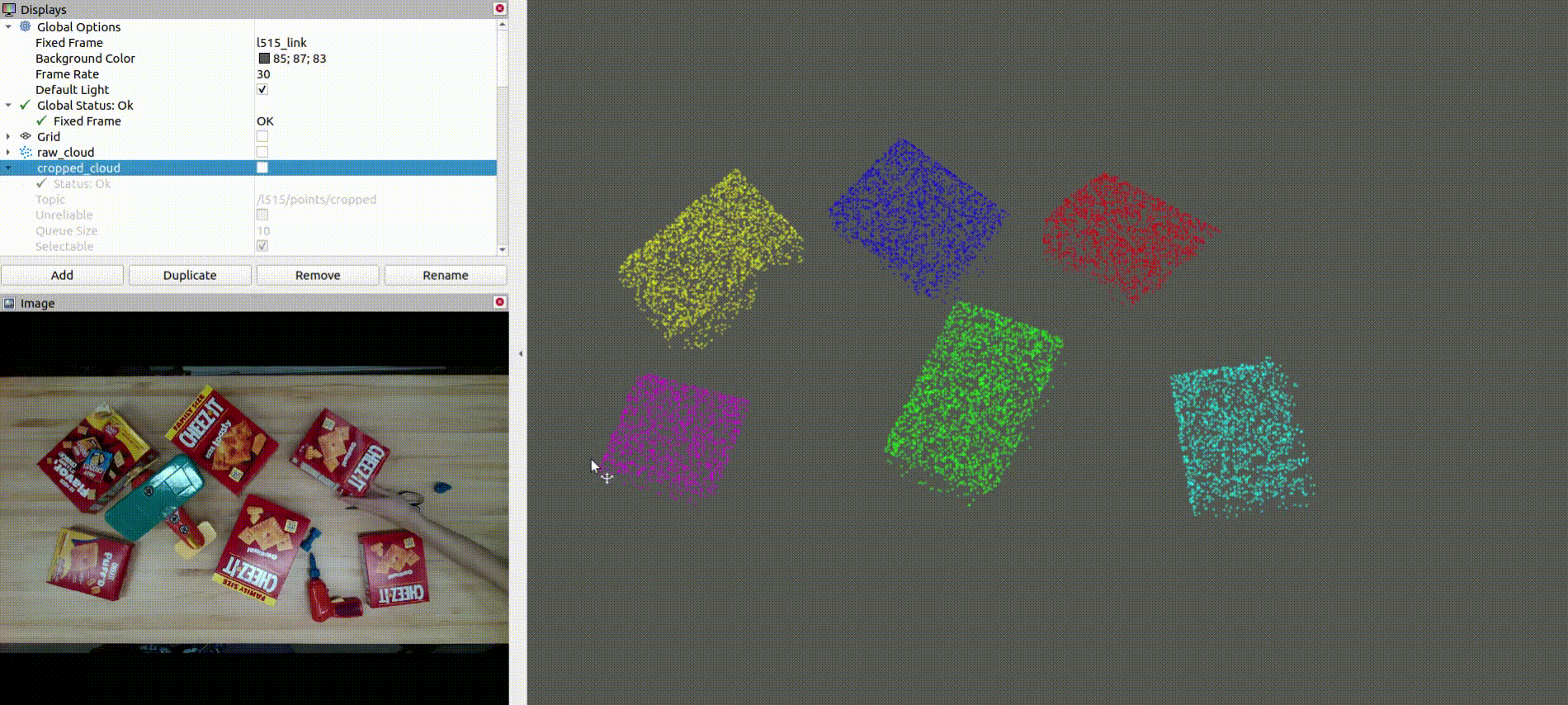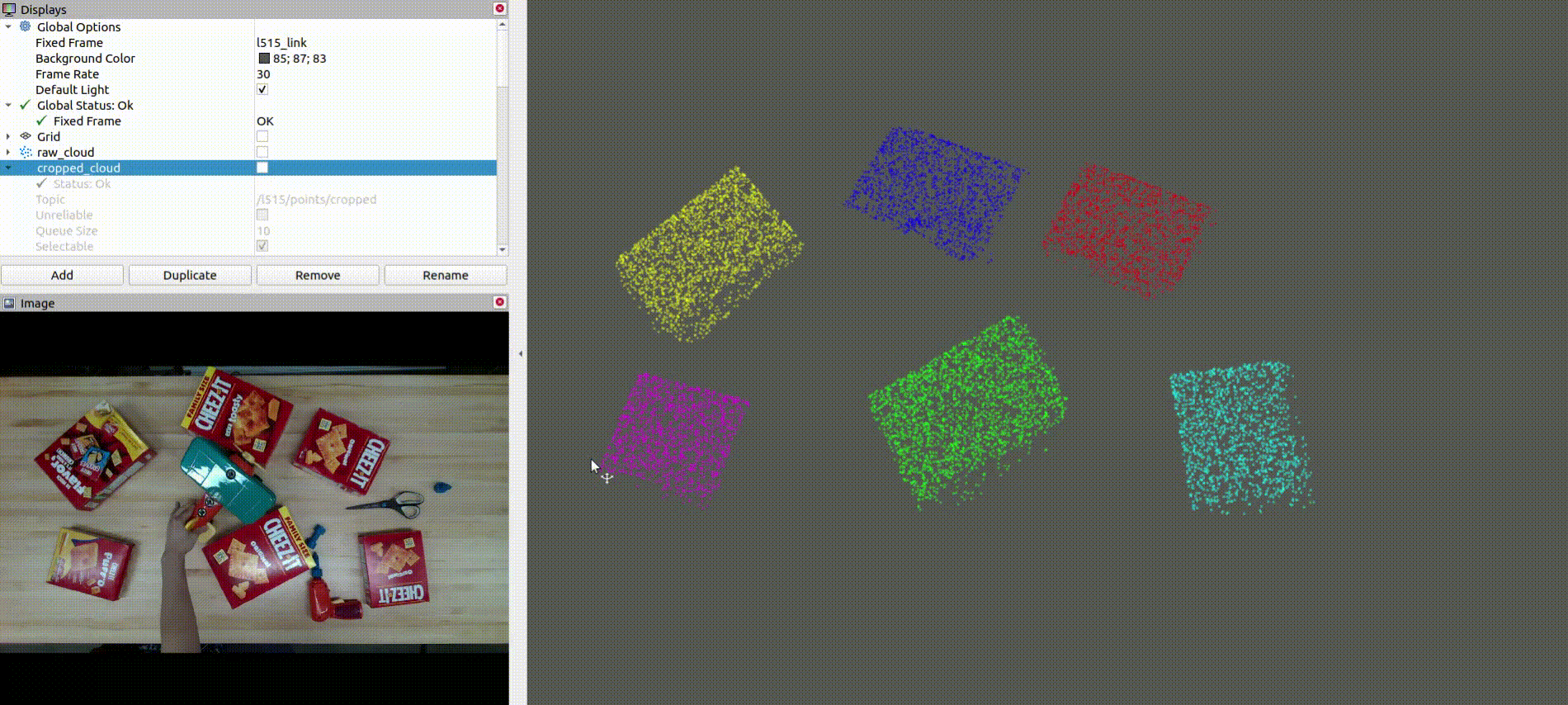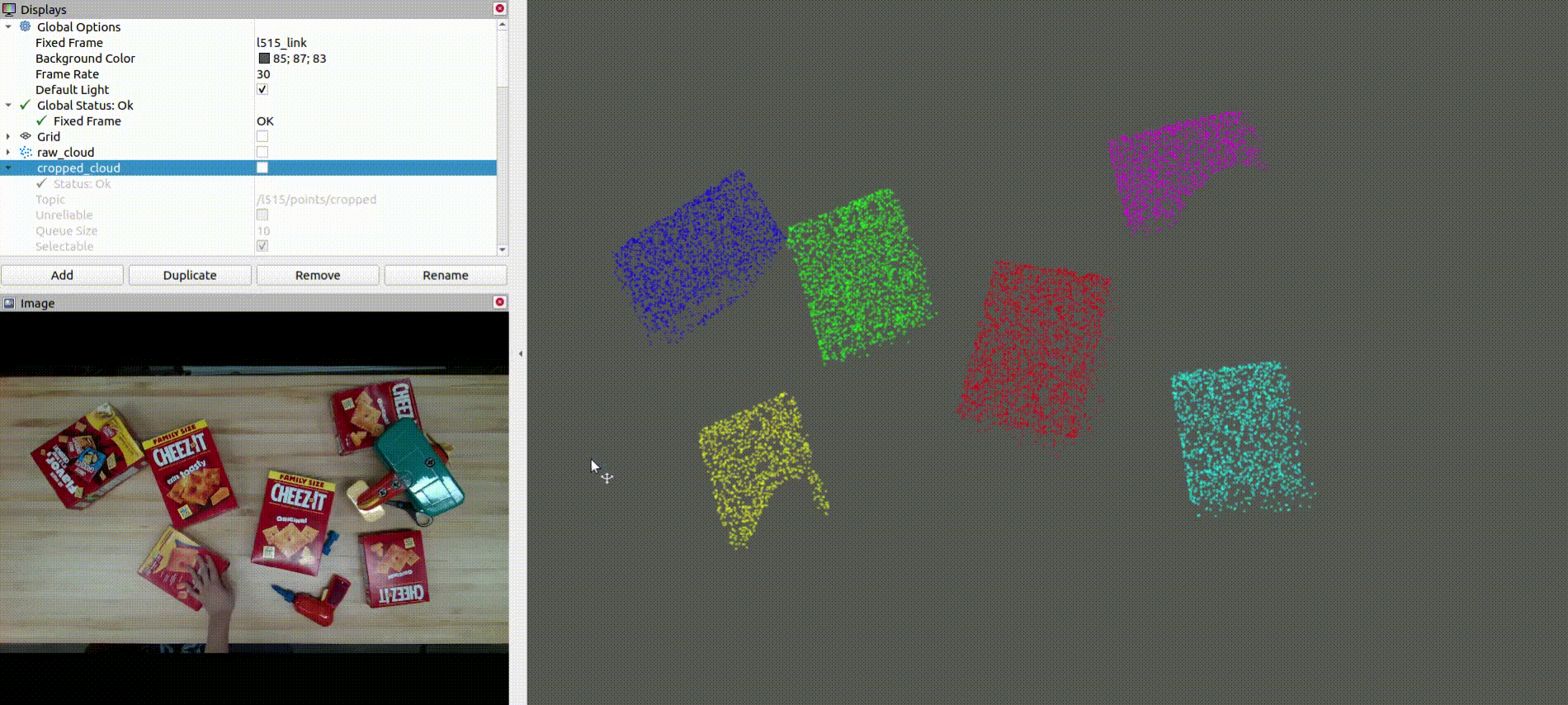
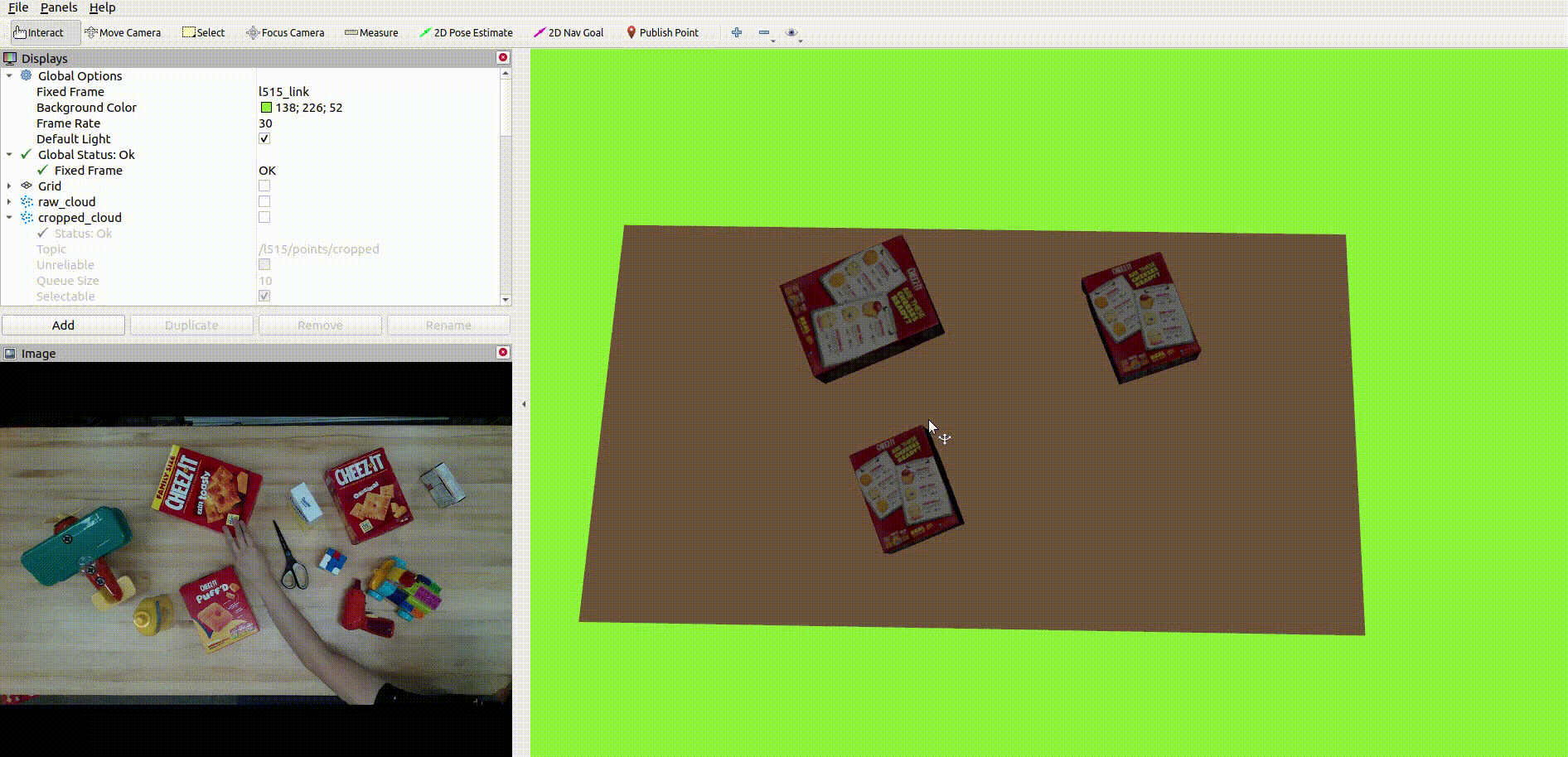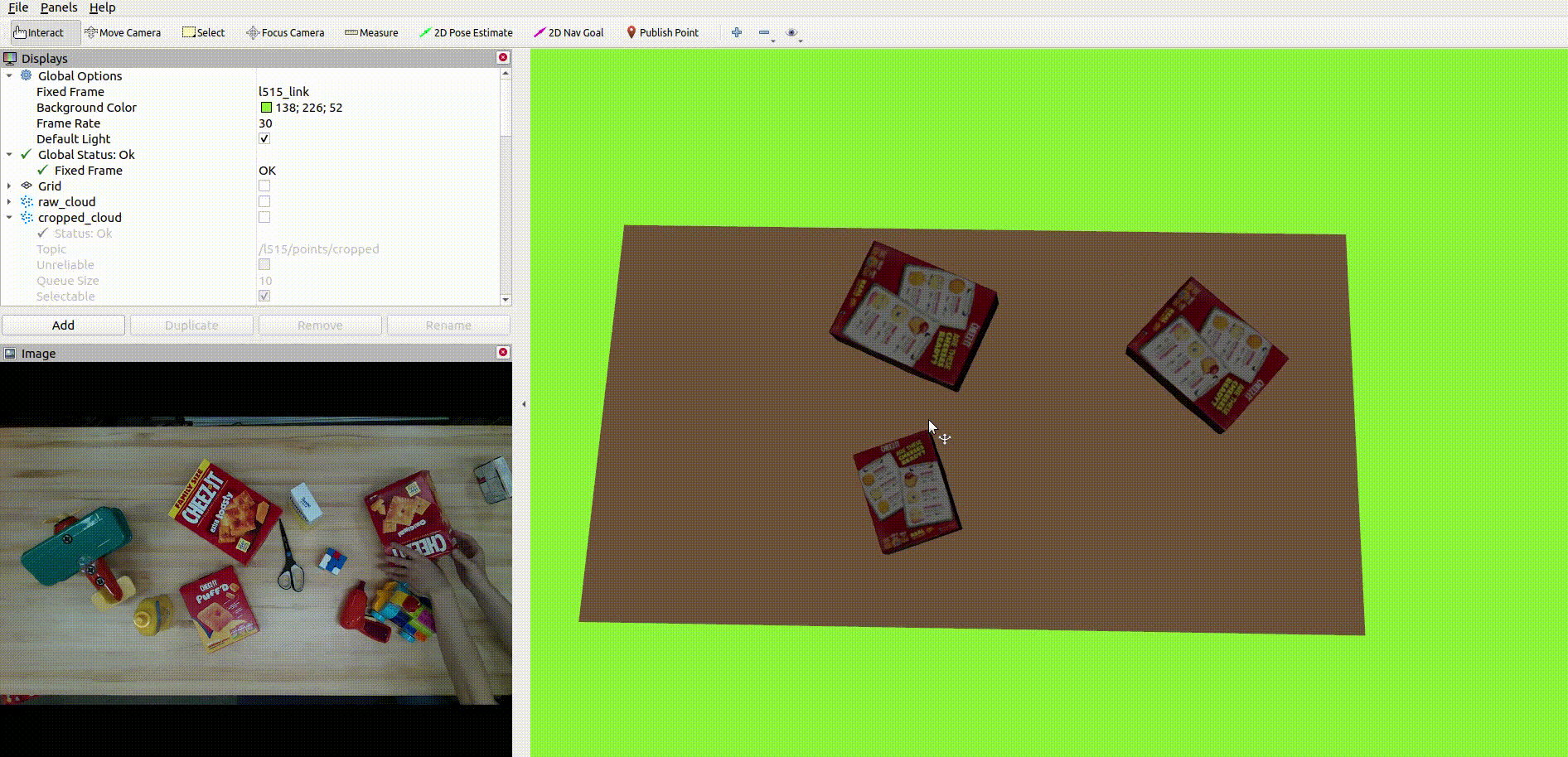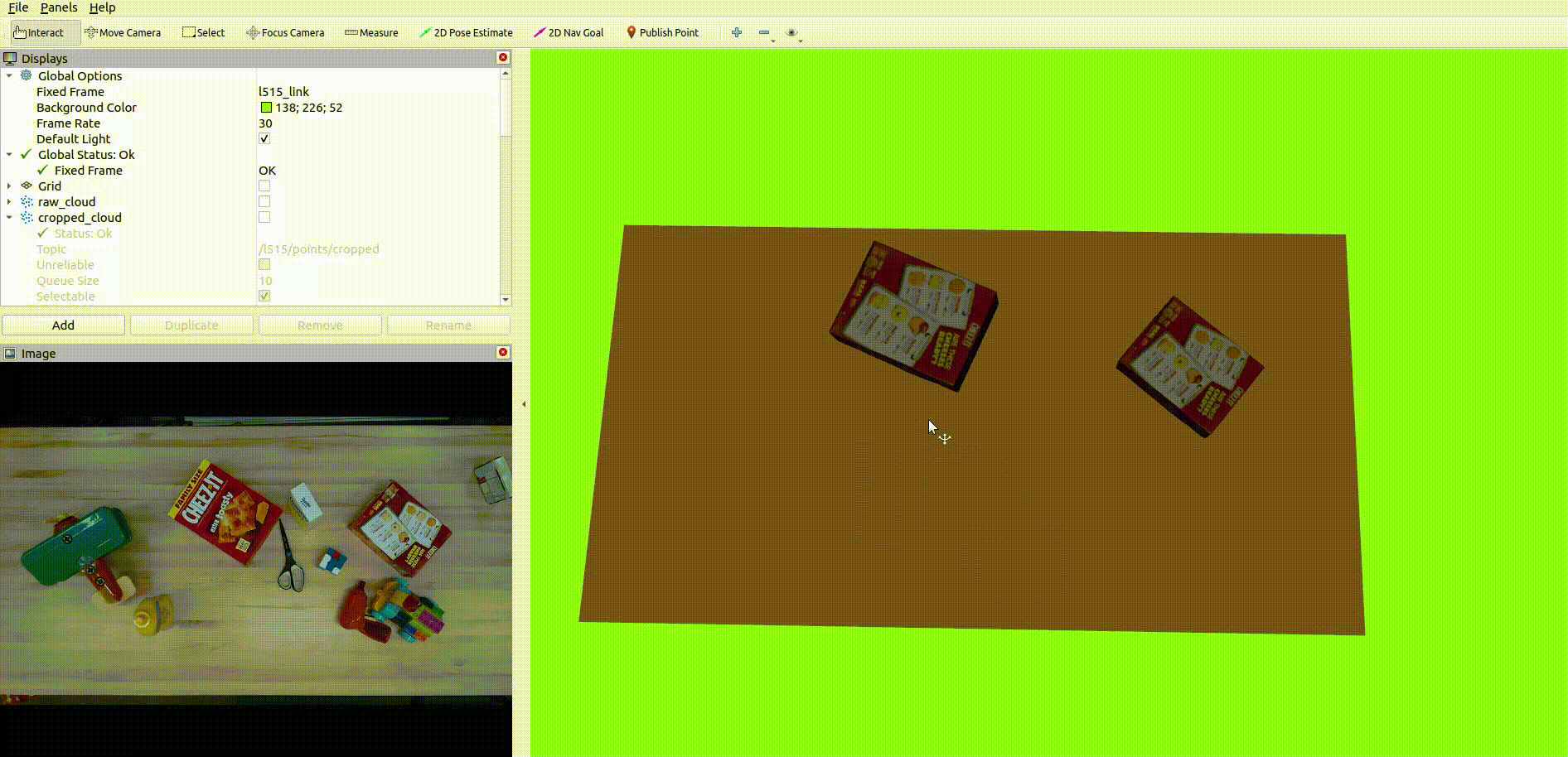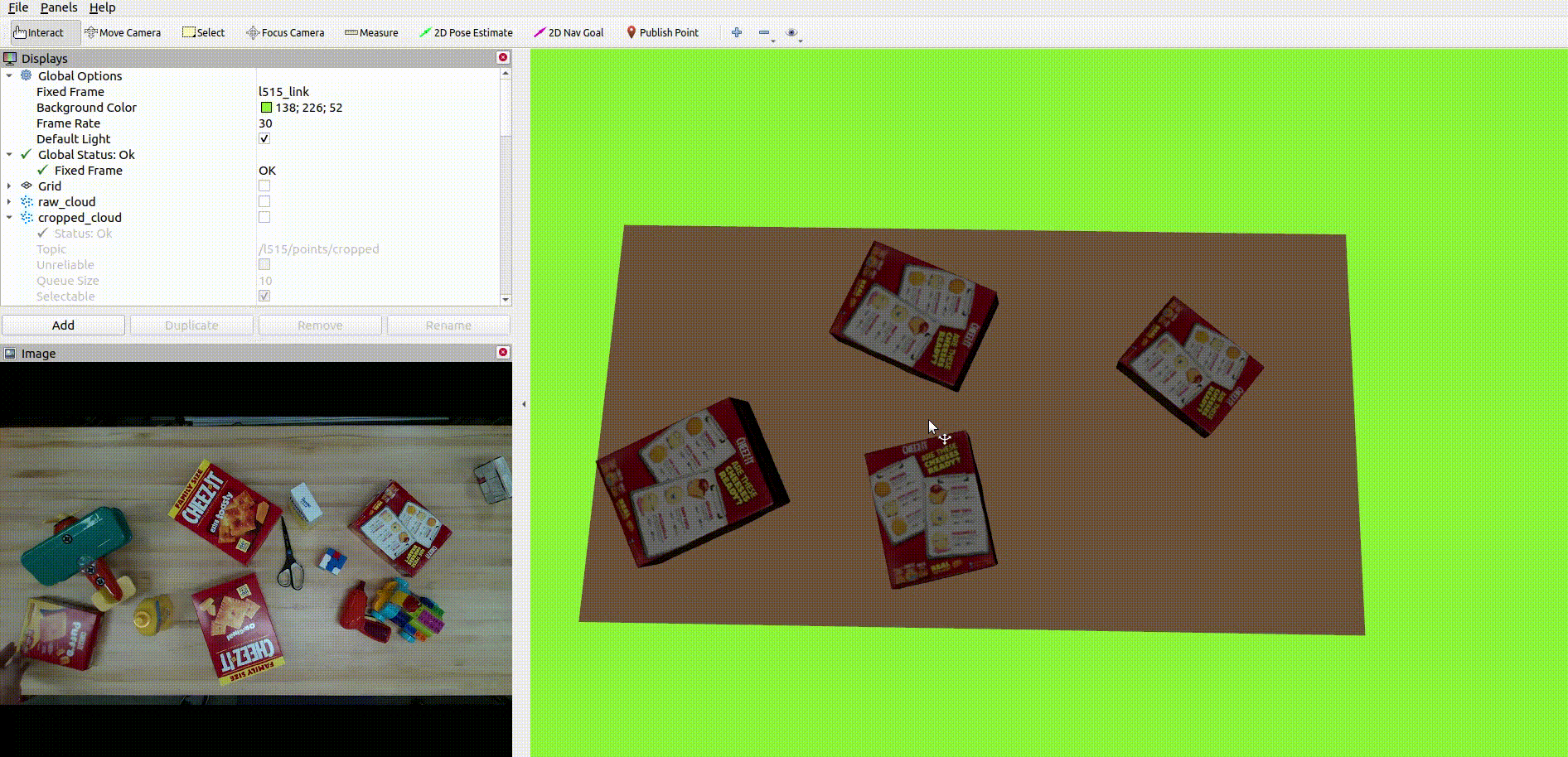
The below image shows the CAD model replacement of the target objects:
Future Scope
- Implement a faster CNN model for instance segmentation such as YOLACT-EDGE to reduce the inference time
- Annotate more images to train a more robust and accurate model
- Annotate the model based on the cropped images to reduce the inference time
- Call the inference server with cropped images to reduce the inference time
- Implement a more robust and accurate pose estimation algorithm, such as point cloud registration
- Multi-thread CPU implementation on the perception core node to reduce the runtime
- Implement some OpenCV and PCL algorithms in GPU to reduce the runtime